

Project Information
- Title: Automated Lip Reading with an Hourglass Network
- Tech: Python (PyTorch, OpenCV, PySpark)
- Date: September 2022 - November 2022
- Report: View PDF
- Presentation: View Slides
- Code: Please reach out! We borrowed heavily from An Efficient Software for Building Lip Reading Models Without Pains, so feel free to start there.
About
For my Computer Vision final project, I teamed up with another student to build an Automated Lip Reading Network.
Motivation
Our motivation stemmed from the many uses of automated lip reading. From recovering text from CCTV videos to live audio-interpretation services for the deaf, automated lip reading is a powerful tool. It is also a common vision problem. The literature points to dozens of papers on the topic.
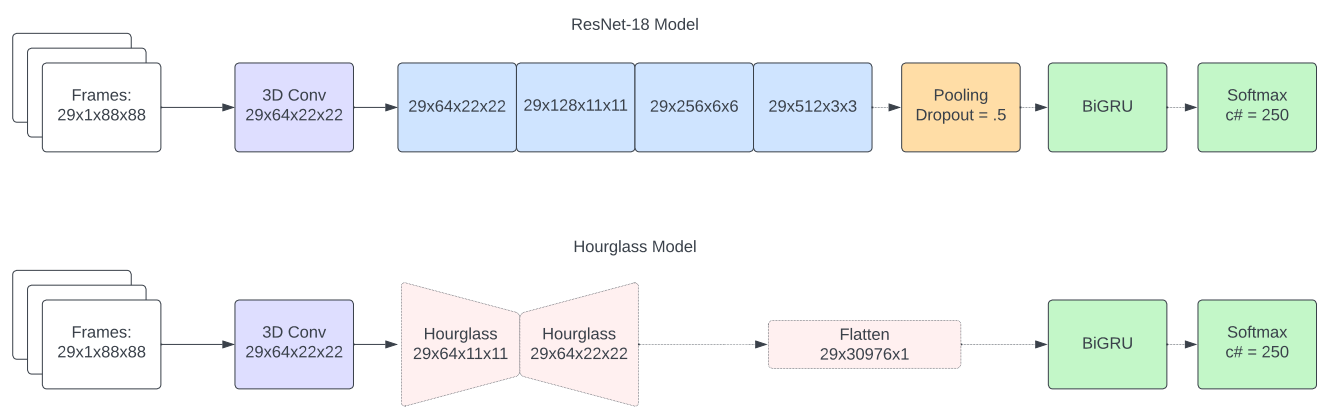
We wanted to build off of the literature by trying to use a stacked hourglass network. Stacked hourglasses were recently found to be effective in human pose estimation (think wooden artist mannequins!) and are excellent at learning movements at different scales. They have not yet been applied to lip reading problems, and we wanted to see if it could pick up both larger facial expressions and the subtle movements of the lips.
Implementation
We started with the LRW dataset which is a collection of videos of 500 spoken English words and is typically the benchmark for lip reading research. The training set contains 800-1000 videos per word, and the validation and test sets include 50 videos per word. The videos primarily come from British news broadcasts.
To validate our model, we compared it with a ResNet-18 model as a baseline as it was found to perform almost as well as the state-of-the-art models in the literature.
The Details
Please take a look at our final report and presentation for more information!